JUC源码详细分析之Part3——《常见的线程安全集合》
本系列笔记笔者将会详细的讲解JUC中核心类的源码,其中基于的JDK版本为
1.8.0_291。由于JUC内容很多,因此笔者将笔记拆为四部分:另外,本系列笔记部分内容参考自《深入浅出 Java Concurrency》
4. 常见的线程安全集合
本章主要讲JUC下部分线程安全的数据结构,我们在日常开发中会经常使用他们,但是关于他们的实现原理与源码很多同学可能没了解过,现在就带大家了解JUC下常用数据结构的源码。
4.1 ConcurrentHashMap
我们之前利用读写锁实现了一个线程安全的HashMap,但是这个Map的性能并不高,因为首先他只支持同一时间一个线程的写入,另外读取的时候也需要加锁读取,在写的时候不允许读取,我们希望一个效率更高的map来替换之前读写锁版本的map,至少他需要改进两个功能:
- 可以支持一定量的并发修改
- 读取的时候不需要加锁
在理解ConcurrentHashMap前,我们默认读者对HashMap的实现是有一定了解的,有HashMap源码的经验,包括JDK1.7和JDK1.8版本不同的实现方式。
同样,ConcurrentHashMap的实现在JDK1.7和JDK1.8版本中也有所不同,我们先来说JDK1.7版本中ConcurrentHashMap的实现。
4.1.1 JDK1.7 ConcurrentHashMap
在JDK1.7中,ConcurrentHashMap的实现采用了锁分段的思想(JDK1.8也是,不过锁的颗粒度不同)。首先我们知道JDK1.7中HashMap是一个数组加链表的结构,假设我们将数组进行拆分,拆成n份,那么其实每一份是一个更小的数组,或者说每一份是一个更小的HashMap。我们将每一份小的HashMap称为段(Segment)。那么如果我们在操作的时候,先定位到使用哪个段,然后再在段内进行线程安全的增删改查。也即,每个段都是彼此并行的,段与段没有交集,这样最多可支持并发为n的写入/删除操作(n为段的数量)。
如:当前Map数组长度2n,将Map分为n个段,那么每个段的数组长度就是2,每个段都可以认为是个小的HashMap,段与段之间并行,段内的元素操作都是线程安全的。
JDK1.7中ConcurrentHashMap的实现,其结构如下:

首先ConcurrentHashMap内包含一个segments,即段数组,它包含16个段,每个段都是一个类HashMap结构,这个结构(Segment)持有一个独占锁,保证在对段进行修改操作时是线程安全的。另外哈希桶的实现(HashEntry)的实现是链表的方式,即相同hash值的节点通过链表串起来(与JDK1.7相同)。
在这里我们引入了段,为了提高map修改时的并发能力,但同样也带来了一个问题:当我们要操作一个元素时,如何定位这个元素在哪个段上,即原来我们只需要定位哈希桶,然后遍历链表节点,现在需要变为段->哈希桶->节点。JDK1.7中的实现依然是通过hash,即先通过hash定位到段,再通过二次hash定位到哈希桶(hashEntry),然后再通过遍历链表得到具体的节点。
了解了上面这些实现,我们可以从另一个角度看一下ConcurrentHashMap。首先ConcurrentHashMap内部有一个HashMap,这个HashMap的key是段号,value值是Segment。同时Segment也是一个HashMap,因此我们可以认为ConcurrentHashMap是一个value为HashMap的HashMap,这样也就不难理解进行元素操作时需要二次hash了。
我们先来看下JDK1.7中ConcurrentHashMap是如何通过key获得段的:
首先会将key值的hashCode(每一个Java Object都有hashCode)通过hash()进行二次编码(哈希算法打散均匀),然后将得到打散后的hash值通过segmentFor()函数,就可以定位到key对应的segments数组对应的数组下角标,返回数组下角标出处的Segment即可。熟悉HashMap的同学不难发现这与HashMap获得哈希桶的方式一模一样。
//hash算法,打散key的hashcode
private static int hash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
//通过hash得到数组的index,返回Segment
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}与HashMap中的哈希桶数组不同,segments不支持resize操作,也即segments的大小一旦初始化无法修改。
了解了这个后我们再来看下JDK1.7下的ConcurrentHashMap的增删改查:
get
我们之前已经讲了如何获得Segment,这里的get操作是获得Segment后的get,也即这里的
get()是Segment对象的函数,而非CouncrrentHashMap的函数,下面讲的put()、remove()同理,不再赘述。V get(Object key, int hash) { //count变量是指段内的元素个数,如果元素个数为0,代表没有可读的直接返回 if (count != 0) { //getFirst函数就是根据当前hash值得到HashEntry,即哈希桶的头结点 HashEntry<K,V> e = getFirst(hash); //当头节点不为空就开始遍历链表 while (e != null) { if (e.hash == hash && key.equals(e.key)) { //找到这个节点,如果节点value不为空就返回 V v = e.value; if (v != null) return v; //否则加锁再读一遍 return readValueUnderLock(e); } e = e.next; } } return null; } //getFirst操作 得到当前hash值所在的HashEntry头结点 HashEntry<K,V> getFirst(int hash) { HashEntry<K,V>[] tab = table; return tab[hash & (tab.length - 1)]; } //如果读取的值为null,加锁再读一遍 V readValueUnderLock(HashEntry<K,V> e) { lock(); try { return e.value; } finally { unlock(); } }这里唯一比较特殊的是
readValueUnderLock(e)处的代码,在读到value为空时,还要加锁再读一遍,这是为什么呢?这与value的修改对当前线程还不可见有关,我们会在下面的put操作时详细解释。put
V put(K key, int hash, V value, boolean onlyIfAbsent) { //由于修改段结构,因此加锁 lock(); try { int c = count; //如果当前段内元素大于阈值,进行rehash操作 if (c++ > threshold) // ensure capacity rehash(); //得到当前key的hash值对应的HashEntry HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; //如果e!=null,代表当前有与当前hash相同的节点,因此遍历这个链表,直到找到一个与当前节点相同的节点或遍历到最后一个空节点(此时e==null) while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; //e!=null 代表当前put的这个值是已经存在的 if (e != null) { oldValue = e.value; //如果onlyIfAbsent = false 就更新这个值 否则什么也不干 //这里那么做的原因是为了实现putIfAbsent函数 if (!onlyIfAbsent) e.value = value; } //否则 即e==null 代表当前段内没有与当前要插入的节点相同的元素 else { oldValue = null; //修改modCount的值 ++modCount; //将当前节点构造为HashEntry,并设为这个链表的头结点,加入到哈希数组中。 tab[index] = new HashEntry<K,V>(key, hash, first, value); //回写count的值(或者说修改count的值) count = c; // write-volatile } return oldValue; } finally { unlock(); } }可以看到put整个操作都是加锁的,因此针对一个段的修改是线程安全的,这里我们就需要讲下在
get()操作时留下的那个问题:在读到value为空时,还要加锁再读一遍,这是为什么呢?这与
tab[index] = new HashEntry<K,V>(key, hash, first, value);这段代码有关。这段代码做的是将当前元素构造为HashEntry并设为整个链表的头结点,然后将这个新的链表加入到数组中。这里会存在一个重排序的问题:理论上,我们是先new了这个HashEntry,然后将数据赋给HashEntry对象,再将这个HashEntry赋给tab[index],即new HashEntry() -> 给 HashEntry赋值 ->设置进tab[index],但编译器有可能会对这个顺序进行重排,重排后顺序为:new HashEntry() ->设置进tab[index]-> 给 HashEntry赋值 。这样就会存在一个问题:如果我们将HashEntry设置进tab[index]后,设置了HashEntry的key但还没设置value时,此时进来了查询语句,想象会发生什么?查询会查到这个key值对应的value是null,因为我们还没来得及赋值。因此在get操作时,如果读到的value是null,执行了
readValueUnderLock()函数,这个函数会加锁,如果此时我们正在写入,那么这个函数会等到写入完后再重新读取一遍value。remove
V remove(Object key, int hash, Object value) { //首先加锁 lock(); try { //修改count的值 int c = count - 1; //寻找当前key值对应的HashEntry节点 HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; //遍历这个链表 一直找到我们要删除的节点或者找到一个空节点为止 while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue = null; //不等于null 代表找到了 if (e != null) { V v = e.value; //ConcurrentHashMap的remove有一个参数为value,如果这个value传null代表不关心value,找到key值相同的节点删除即可 //但如果value!=null 代表调用者不仅要求key相同,还需要这个节点的key对应的value也是自己想要的value,只有这种情况下才会执行删除操作 if (value == null || value.equals(v)) { oldValue = v; ++modCount; //从原来链表中删除当前节点并且构造成新的链表赋值进tab数组。 HashEntry<K,V> newFirst = e.next; for (HashEntry<K,V> p = first; p != e; p = p.next) newFirst = new HashEntry<K,V>(p.key, p.hash, newFirst, p.value); tab[index] = newFirst; count = c; // write-volatile } } return oldValue; } finally { unlock(); } }删除操作需要提及的是
if (value == null || value.equals(v)) { oldValue = v; ++modCount; //从原来链表中删除当前节点并且构造成新的链表赋值进tab数组。 HashEntry<K,V> newFirst = e.next; for (HashEntry<K,V> p = first; p != e; p = p.next) newFirst = new HashEntry<K,V>(p.key, p.hash, newFirst, p.value); tab[index] = newFirst; count = c; // write-volatile }这段代码,对于为什么if我们在注释中已经解释了,这里需要解释的是:如何从链表中删除一个节点?ConcurrentHashMap会先将当前节点的继任节点取出作为新链表的头结点,假设这样形成的链表我们命名为C,然后从原来的头结点开始遍历,每遍历一个节点都将这个节点设为链表C的头结点,直到遍历到当前节点为止,这样得到新的链表赋给原来的tab[index]即可。流程大概如下图:


假设我们要从链表B1->B2->B3->B4->B5 中删除删除B3,那么先将B4设为新链表的头结点,即B4->B5,然后从原来的头结点开始遍历,即B1,每遍历一个节点都将这个节点设为新链表的头结点,此时新链表就是B1->B4->B5。 然后是 B2->B1->B4->B5,此时新的链表形成,将这个新的链表赋给table[index]。
这里大家可能会有几个问题:
为什么要这么做?
在其他链表结构中,如果删除链表中的节点,很可能是B3->pre->next = B3->next即可。但ConcurrentHashMap内的元素节点没有pre指针,另外他们的next指针都是final的,这样,链表结构如果变动只能重新生成节点。
如果我们在删除节点的时候发生了读事件,读到的会是什么情况?
如果新的链表还没设置进table,那么读取时会用旧的链表来读取,自然读到的是旧数据。也即旧的链表在新的链表生成过程中是依然存在的,这样做可以保证在删除时读操作依旧能读到数据,只不过可能不是最新的。旧的链表会在我们将新链表设置进table[index]后失去引用,然后被GC回收。
这样我们就完成了ConcurrentHashMap的增删改查操作,这里还有一些需要注意的细节:
当我们对一个段进行操作时,对段的修改操作由于加了锁因此保证同时只能有一个线程在修改段,但读取是没有加锁的,因此可以有多个线程同时读取段。为了让修改线程修改的内容能被读取线程看到,一些字段就需要设置为volatile,如Segment中的count,table属性,HashEntry中的value属性。在对volatile字段进行更新时,代码基本上都是先建立一个临时变量指向volatile变量,然后读写操作就在这个临时变量中进行,最后再将这个临时变量赋值给volatile变量。
如:
int c = count - 1;
//寻找当前key值对应的HashEntry节点
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];这样做的原因是多次读取volatile类型的开销要比非volatile开销要大,而且编译器也无法优化,因此建立临时变量,这样多次读写tab的效率要比volatile类型的table要高,JVM也能够对此进行优化。
从这里我们也看出JDK源码编写者们对代码编写的严苛程度。
4.1.2 JDK1.8 ConcurrentHashMap
JDK1.8中也采用分段锁的思想,不过JDK1.8取消了段的概念,加锁的颗粒度设为了每一个哈希桶(也可以理解为HashMap数组中的每一个元素都是独立的加锁),另外JDK1.8中采用synchronized和CAS乐观锁来代替JDK1.7中的独占锁保证线程安全性。当然与HashMap一致的是JDK1.8中ConcurrentHashMap也引入红黑树。
JDK1.8中ConcurrentHashMap的实现极其复杂,其源码有6000多行,内部类有50多个,本篇笔记也只是对JDK1.8的ConcurrentHashMap浅析,主要讲一下常用API的源码:
put
//调用put操作插入KV public V put(K key, V value) { return putVal(key, value, false); }//onlyIfAbsent如果为true则代表只插入不替换,换句话说,如果K存在就不做操作 //如果onlyIfAbsent为false则代表相同的K会替换value final V putVal(K key, V value, boolean onlyIfAbsent) { //ConcurrentHashMap不同于HashMap,不允许key为null if (key == null || value == null) throw new NullPointerException(); //得到key的hash int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; //如果table==null或者tab.length==0代表数组为空,此时就需要初始化 if (tab == null || (n = tab.length) == 0) //数组初始化,后面我们会讲 //数组初始化完成后,数组就不再为空,下一次for循环也就不会再进入当前分支 tab = initTable(); //tabAt操作会获得当前K所在的数组的HashEntry(即这里的Node),并将它赋给f变量 //如果f==null 代表当前K对应的数组index处的元素不存在,因此就需要先初始化 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //new Node即初始化当前节点,然后通过CAS操作将当前Node设置进table //如果CAS成功则当前put操作基本完成,直接到倒数第二行即可 //如果CAS不成功,代表当前有并发操作,下一次的for循环,会走进别的分支 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } //这里的MOVED是-1,如果进入这个分支代表当前正在扩容,那么这个插入节点也会帮着转移数据,这个我们后面会讲 else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { //走到这个分支代表: //1. 数组不为空 //2. 当前tab[index]处元素不为空 //3. 当前Map不是正在扩容 //我们之前说过JDK1.8取消了段的概念,加锁的颗粒度设为了每一个哈希桶 //通过前面代码我们知道f就是哈希桶头节点,因此此处就是通过synchronized锁住头节点保证对哈希桶的加锁 V oldVal = null; synchronized (f) { //加锁后再确认一遍f是当前头节点,因为前面的操作均为加锁,有可能f被删了 //如果f不再是我们的头节点,那么会再次进入下一次的for循环重新获得新的哈希桶头节点 if (tabAt(tab, i) == f) { //走到这里代表加锁后f就是我们的哈希桶头节点 //头节点hash>0说明当前哈希桶的实现是链表 //了解HashMap的知道,JDK1.8中哈希桶有链表和红黑树两种实现且会相互转换 if (fh >= 0) { binCount = 1; //开始遍历链表 for (Node<K,V> e = f;; ++binCount) { K ek; //这个if是说链表中存在节点k与我们要插入的k相等 if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; //如果允许替换就替换了 if (!onlyIfAbsent) e.val = value; //结束for循环,完成插入 break; } //否则走到这代表当前遍历的k不等于我们要插入的k Node<K,V> pred = e; //如果遍历到链表的最后一个节点还没有相等的k, //说明这是个新的k,就将它封装为Node加入到链表的末尾 if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); //结束for循环 完成插入 break; } } } //这里代表fh < 0 代表当前哈希桶是红黑树构成 //这是因为红黑树在构造的时候将红黑树的根节点的hash设置为了-2 //每棵红黑树的根节点都是假节点,这个节点的hash是常量-2 else if (f instanceof TreeBin) { Node<K,V> p; //调用红黑树的插入 binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } //binCount这个变量可以理解为是一个flag,他在初始化的时候是0 //在插入的时候如果是向链表尾部追加节点,此时binCount是1-n(跟链表遍历相关) //在插入的时候如果是向红黑树中追加节点,此时binCount是2 //因此binCount != 0且binCount >=8 则代表一定是向链表尾追加了节点 //此时就会触发红黑树与链表的转换,会将链表转为红黑树 if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) //这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换 // 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } //更新记录并判断是否需要扩容,如果需要就扩容 addCount(1L, binCount); return null; }上述便是put流程的主要代码,我们可以做个流程总结:
- 如果key或value为null,抛出异常,否则执行步骤2
- 如果数组为空,则初始化数组,然后执行步骤2,否则执行步骤3
- 如果key所对应的Node不等于空,执行步骤4。否则创建一个Node并插入到哈希数组中,如果插入成功执行步骤7,如果插入失败则执行步骤2。
- 如果哈希正在扩容则帮助扩容迁移,然后执行步骤2,否则执行步骤5
- 如果Node不是头节点了,执行步骤2。否则如果Node是链表将节点插入到链表尾,如果Node是红黑树则将节点插入到红黑树中,然后执行步骤6
- 如果刚才插入到的是链表尾部且链表长度大于等于8则执行扩容或链表转红黑树操作,然后执行步骤7
- 更新记录并判断是否需要扩容,如果需要就扩容
上面有几点比较重要的我们需要细说:数组初始化,扩容,帮助数据迁移
数组初始化
//数组初始化操作是需要线程安全的,因为可能会有多个线程想要同时执行数组初始化 //那么怎么保证这种线程安全呢?加锁是最简单的,下面函数的实现虽然没有使用锁但使用了锁的核心思想 //在前面Lock的学习中,我们知道锁就是一个标志位,现在这个标志位就是sizeCtl,将sizeCtl设置为-1的线程代表获得了锁 //有了这个基础我们看下数组初始化的实现 private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; //由于是CAS操作,所以需要循环保证重试 while ((tab = table) == null || tab.length == 0) { //如果此时sizeCtl已经小于0,代表已经有线程持有锁了,当前线程就需要yield,让抢到锁的线程去初始化。 if ((sc = sizeCtl) < 0) Thread.yield(); // lost initialization race; just spin //如果sizeCtl还不是-1,代表锁还未被抢到,此时当前线程尝试设置SIZECTL为-1来获得锁 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { //获得锁成功后开始执行初始化操作 if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; //这里相当于sc = n- n/4,也即sc = 0.75n,其中0.75是负载因子 sc = n - (n >>> 2); } } finally { //初始化完成恢复sizeCtl sizeCtl = sc; } break; } } return tab; }链表转红黑树时会发生扩容的可能
//将链表转为红黑树 private final void treeifyBin(Node<K,V>[] tab, int index) { Node<K,V> b; int n, sc; if (tab != null) { //如果数组长度小于64会走扩容流程,不转红黑树 if ((n = tab.length) < MIN_TREEIFY_CAPACITY) //扩容,数组大小扩容1倍 tryPresize(n << 1); //获得头节点 else if ((b = tabAt(tab, index)) != null && b.hash >= 0) { //加锁头节点,避免线程安全 synchronized (b) { //再次判断b是否是头节点 if (tabAt(tab, index) == b) { //遍历链表转红黑树 TreeNode<K,V> hd = null, tl = null; for (Node<K,V> e = b; e != null; e = e.next) { TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null); if ((p.prev = tl) == null) hd = p; else tl.next = p; tl = p; } //将新的红黑树数据结构设置进数组 setTabAt(tab, index, new TreeBin<K,V>(hd)); } } } } }//resize操作 private final void tryPresize(int size) { int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1) + 1); int sc; while ((sc = sizeCtl) >= 0) { Node<K,V>[] tab = table; int n; if (tab == null || (n = tab.length) == 0) { n = (sc > c) ? sc : c; if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if (table == tab) { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; } } } else if (c <= sc || n >= MAXIMUM_CAPACITY) break; else if (tab == table) { int rs = resizeStamp(n); if (sc < 0) { Node<K,V>[] nt; if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0) break; if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) transfer(tab, nt); } else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) transfer(tab, null); } } }
4.2 ConcurrentLinkedQueue
ConcurrentLinkedQueue是一个链表实现的线程安全的队列,队列内元素的顺序就是入队列的顺序,队列头是队列内时间最久的,而队列尾就是队列中时间最短的。
通过我们前面对锁的学习,可以设想下实现一个线程安全的队列有几种方法:
- 使用synchronized来同步队列
- 使用Lock,用读写锁或独占锁。
- 使用乐观锁CAS和不断循环的方式。
ConcurrentLinkedQueue是通过第三种方案CAS来实现线程安全的。
ConcurrentLinkedQueue内部的属性比较简单,主要的属性只有两个,节点头和节点尾
private transient volatile Node<E> head;
private transient volatile Node<E> tail;其中Node类结构更加简单,只有value和next指针,这里可以看到ConcurrentLinkedQueue是一个单向链表。
private static class Node<E> {
volatile E item;
volatile Node<E> next;
}正常的增加和删除节点只能操作头结点和尾节点,如果想操作中间节点必须要遍历这个队列。
这里所有的属性都是volatile类型,因为ConcurrentLinkedQueue是非阻塞的,需要保证写入可以被后续的读取看到,同时避免重排序。
队列的头节点是无意义节点也即伪节点,当类初始化的时候,会初始化一个无意义节点赋值给head和tail指针,但当插入一条数据后会修改tail指针的值,将tai指针变得有意义。也即head指针一直都是无意义的,当队列内有数据时tail指针就是真实的最后一个数据,但当队列内无数据,tail=head=伪节点。
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}队列的插入:
todo:看不懂里面的逻辑
//向队列尾插入一条数据
public boolean offer(E e) {
//校验数据非空
checkNotNull(e);
//将数据封装为node节点
final Node<E> newNode = new Node<E>(e);
//将tail赋给p
//这里的逻辑会有些复杂,首先我们需要明确tail指针指向的永远都是尾节点那个元素,这时候将t和p都指向当前tail指针指向的那个元素
//但如果此时有别的线程修改了尾节点,那么自然tail指针指向的节点也会被修改,那t和p指向的就不再是新的尾节点了,而还是之前那个旧的尾节点
//此时p==t!=tail了。 这有点类似于tail->Obj1,t = tail,此时t->obj1,而p = t ,p->obj1,
//此时有个线程修改了tail的指向 tail->obj2,但p和t都未被修改,还指向之前的obj1
for (Node<E> t = tail, p = t;;) {
//得到尾节点的next指针,赋值给q
Node<E> q = p.next;
//只有next为空的时候才操作
if (q == null) {
//将当前节点设为p的next指针,当且仅当p.next==null才操作
if (p.casNext(null, newNode)) {
if (p != t)
casTail(t, newNode);
return true;
}
}
else if (p == q)
p = (t != (t = tail)) ? t : head;
else
p = (p != t && t != (t = tail)) ? t : q;
}
}出队列:
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
if (p != h)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}遍历数组的大小
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = p.getNext()) {
if (p.getItem() != null) {
// Collections.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
}
}
return count;
}4.3 阻塞队列 BlockingQueue
阻塞队列就是会对元素的入队和出队操作在不满足条件时进行阻塞。比如如果队列在无元素时执行出队列操作,那么会一直阻塞到队列内有可出队列的元素为止。
阻塞队列有两个方法 put和take即阻塞的入队和出队操作。阻塞队列的使用场景非常普遍,最常见的就是生产消费模型,生产者生产信息往队列中put,当队列满了就需要阻塞,消费者消费数据就是从队列中take,如果队列内无可取的元素就阻塞直到有元素。
在JUC中对于阻塞队列有几种不同的实现,下面我们一一看下。
4.3.1 LinkedBlockingQueue
LinkedBlockingQueue内部属性如下:
//队列的容量 当队列满了后再put就会阻塞
private final int capacity;
//队列当前实际元素的数量
private final AtomicInteger count = new AtomicInteger();
//头节点
transient Node<E> head;
//尾节点
private transient Node<E> last;
//取锁
private final ReentrantLock takeLock = new ReentrantLock();
//notEmpty信号量
private final Condition notEmpty = takeLock.newCondition();
//写锁
private final ReentrantLock putLock = new ReentrantLock();
//notFull信号量
private final Condition notFull = putLock.newCondition();Node节点的信息如下
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}LinkedBlockingQueue内部维持了一个线程安全的count,这不像ConcurrentLinkedQueue需要遍历整个队列得到size。另外LinkedBlockingQueue内部维护了两个锁,一个是take时的锁一个是put时的锁。在ConcurrentLinkedQueue中我们知道,其实出入队列基本是相互分离不干扰的,出队列就是操作head,而入队列是操作tail,因此我们可以认为take和put操作是互不干扰的,也即可以并行执行的。通过两个锁保证入队和出队不互相影响,提高了吞吐率。
入队列:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
//将当前元素封装为节点
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
//加锁 直到线程被中断
putLock.lockInterruptibly();
try {
//如果满了就挂起 通过条件变量notFull挂起
//注意这里用了while没用if 这一原因我们之前说过
while (count.get() == capacity) {
notFull.await();
}
//走到这里代表当前队列不满,执行入队列操作
enqueue(node);
//先将count的值赋给c,然后再将count+1,这里记住是先赋给c,再加1
c = count.getAndIncrement();
//如果没满发布notFull 唤醒因为notFull阻塞的线程
if (c + 1 < capacity)
notFull.signal();
} finally {
//释放锁
putLock.unlock();
}
//因为上面是先赋给c再加1,所以c==0代表之前队列是空的,但现在put进来了元素,所以需要唤醒因为队列为空而挂起的消费线程
if (c == 0)
signalNotEmpty();
}
//入队列函数 比较简单不再解释
private void enqueue(Node<E> node) {
last = last.next = node;
}
//发布非空,简单的lock与condition配合的场景
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}这里需要考虑的一点是为什么
if (c + 1 < capacity)
notFull.signal();有这样一段代码。为什么我们在入队的时候还需要唤醒其他入队挂起的线程,正常来说入队的线程不是应该由出队线程唤醒吗?
这是因为出队线程出队成功后,判断如果之前队列是满的,确实会执行唤醒操作,但执行的是signal()而非signalAll()(一会我们会看到)signal()存在一个问题是可能不一定成功唤醒这个线程,如果没有成功唤醒,那么这些线程还在挂起,此时入队的线程如果发现可以继续入队,那么他也会尝试唤醒,这样避免了因为出队线程signal()不成功而入队线程挂起过久的情况。
我们来看下signal()为什么可能唤醒不成功?
假设我们现在有两个线程A、B正在被条件变量挂起,但他们的条件不同,如:
A:
while(x >10){
condition.await();
}
B:
while(x > 5){
condition.await();
}此时线程C执行signal()操作,JVM会随机选择一个挂起的线程唤醒,假设此时选择了B线程唤醒,但因为x是7,所以B在唤醒后会继续await()挂起,但此时线程A因为没接收到通知,还在挂起等待唤醒,即使A应该醒来了。
还一种情况是,我们唤醒了生产者B线程,但此时B抛出了异常,那么按理挂起的A可以接着生产,但因为没有被通知,还是会被挂起。
因此这里多一个signal()操作可以避免线程唤醒失败导致其他挂起线程等待过久的情况。另外为什么选择用signal()而不用signalAll()?如果使用signalAll()全都通知到,似乎就不存在上面说的问题了。
假设此时队列是满的,因为队列满挂起了10000个生产者线程,然后此时消费者消费了一个元素,执行signalAll()操作,想象一下会发生什么?10000个线程都会醒来,为了这一个可生产的位置不断的尝试抢占锁,但最多只有一个线程能获得锁,其他线程又会被再次挂起,这样就会带来大量的上下文切换消耗,这一现象有个比较专业的名词叫惊群
出队列:
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
//加锁
takeLock.lockInterruptibly();
try {
//如果队列内没数据 挂起
while (count.get() == 0) {
notEmpty.await();
}
//被唤醒后进行出队列操作
x = dequeue();
//同put操作,是先赋值再做减操作
c = count.getAndDecrement();
if (c > 1)
//如果队列内依然有数据 进行非空通知
notEmpty.signal();
} finally {
takeLock.unlock();
}
//如果之前队列是满的,现在我们take走了一个元素,因此需要唤醒因为队列满了而挂起的生产线程
if (c == capacity)
signalNotFull();
return x;
}
//出队列 因为队列在初始化的时候有一个假节点 也即队列的头结点永远是假节点
//当出队列的时候,会先将当前队列头节点释放掉 然后取出真实头结点 将真实头结点的值返回 然后再将当前真实头结点变为新的假节点
private E dequeue() {
Node<E> h = head;
Node<E> first = h.next;
//释放假的头结点
h.next = h; // help GC
head = first;
//将真实数据返回
E x = first.item;
//将刚才的真实头结点变为新的假节点
first.item = null;
return x;
}这里比较有意思的一点是在删除的时候,将真实的头结点变为新的假头结点,而不像更简单的:fakeNode->next = fakeNode->next->next这种操作,这种操作看起来更简单,一直保留这个假节点,删除的时候将真实节点从中删掉就好了,这样更方便不是吗?
想象这样一种情况,当前队列内只有一个元素,那么我们队列的结构就会如下:
fakeNode->next = node;
last = node;
node->next = null;如果先执行take再执行put操作时,take操作按照fakeNode->next = fakeNode->next->next,那么就变成
//take
fakeNode->next = fakeNode->next->next;
//put
last->next = newNode;
last = newNode;take操作时,因为队列内只有一个元素,那么take之后fakeFirst->next = null,此时队列情况为:
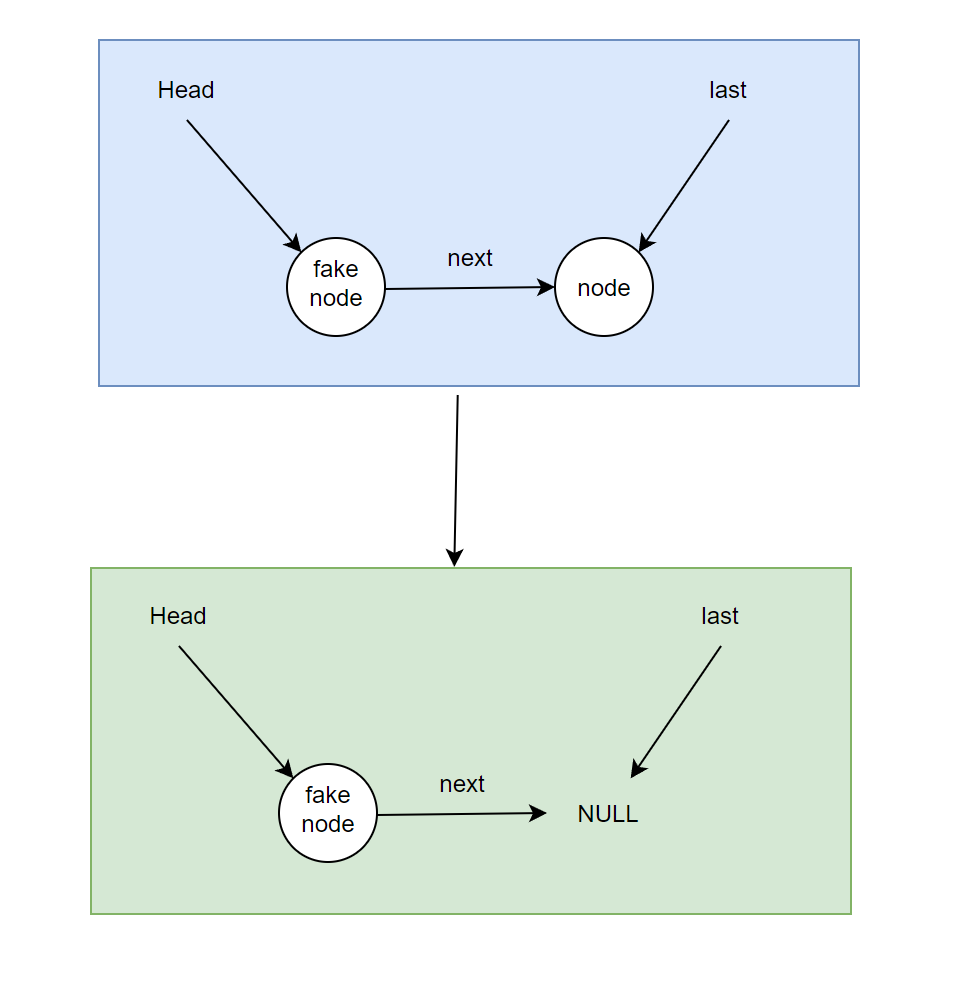
当再执行put操作时: last.next = node;。但此时last指针的指向是NULL,last.next会报NullPointerException。
因此,这里删除选择的是替换新的伪节点的方法。这样在队列内没有元素时,last->next = newNode,这个last指针和当前first指向同一个节点,那么也就代表fakeFirst->next = newNode(保证在队列为空时,head和last都指向fake节点)。
4.3.2 ArrayBlockingQueue
实现队列的方式无非两种:链表和数组。上面我们讲的是链表实现了一个阻塞队列,这里我们讲如何通过数组实现一个阻塞队列。
在讲数组实现阻塞队列前我们先讲下数组如何实现一个FIFO队列:
- 首先我们需要两个指针,分别是header和tail指针,由于数据结构是数组,因此我们的指针只需要是数组索引(下角标)即可。
- 当出队列一个元素时,header指针向后移动(索引+1),并返回旧header索引处的值,然后将旧heaer索引处的值设为null
- 当入队列一个元素时,tail指针向后移动(索引+1),将新元素添加到tail指针指向的新位置。
- 如果header或tail移动到了数组的尾巴,再移动时就从索引0开始,这样就形成了一个环形数组。
- 如果数组满了,那么就拒绝入队或扩容数组。
其代码如下:
/**
* 通过数组实现一个FIFO队列
* @author coderZoe
* @date 2021/12/29 16:46
*/
public class QueueTest<E> {
/**
* 装元素的数组
*/
private final Object[] elementData;
/**
* 当前数组容量
*/
private final int capacity;
/**
* 头指针 用于出队操作
*/
private int header;
/**
* 尾指针 用于入队操作
*/
private int tail;
/**
* 当前队列的实际数量
*/
private int count = 0;
public QueueTest(int capacity) {
this.capacity = capacity;
this.elementData = new Object[capacity];
this.tail = -1;
this.header = 0;
}
/**
* 入队列
* @param element 元素
*/
public void enq(E element){
if(count==capacity){
throw new RuntimeException("队列已满无法入队");
}
tail = increment(tail);
this.elementData[tail] = element;
count++;
}
/**
* 出队列
* @return 返回出队列的元素
*/
public E deq(){
if(count==0){
throw new RuntimeException("队列内无元素 无法出队");
}
E element = (E) this.elementData[header];
this.elementData[header] = null;
header = increment(header);
return element;
}
private int increment(int index){
return (index+1)%capacity;
}
}
有了这个基础,我们再来看ArrayBlockingQueue的实现,其属性如下:
//数组
final Object[] items;
//出队列索引
int takeIndex;
//入队列索引
int putIndex;
//当前数组实际个数
int count;
//锁 独占锁
final ReentrantLock lock;
//非空条件 用于出队阻塞
private final Condition notEmpty;
//非满条件 用于入队阻塞
private final Condition notFull;入队:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
//加锁
lock.lockInterruptibly();
try {
//如果满了就阻塞
while (count == items.length)
notFull.await();
//入队
enqueue(e);
} finally {
lock.unlock();
}
}
//入队操作
private void enqueue(E x) {
final Object[] items = this.items;
//填入信息
items[putIndex] = x;
//环形数组
if (++putIndex == items.length)
putIndex = 0;
count++;
//通知因empty挂起的出队线程
notEmpty.signal();
}出队:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
//加锁
lock.lockInterruptibly();
try {
//如果队列为空 阻塞
while (count == 0)
notEmpty.await();
//进行出队
return dequeue();
} finally {
lock.unlock();
}
}
//出队操作
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//出队 旧值设空 释放内存
E x = (E) items[takeIndex];
items[takeIndex] = null;
//循环数组
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
//通知因队列满了而挂起的入队线程
notFull.signal();
return x;
}4.3.3 PriorityBlockingQueue
JDK中有一个数据结构叫PriorityQueue,即优先队列,这是一个有序的队列(部分有序),使用者在创建的时候需要指明排序方式(或元素自身实现了Comparable)。每次入队的时候,都会排序将元素插入到正确的位置,出队的时候出的是队列内的第一个元素(即排序后最小的元素)。理解PriorityBlockingQueue前我们先实现PriorityQueue,这会使我们更容易理解PriorityBlockingQueue的源码。
PriorityQueue本质是一个完全二叉树(二叉堆),且树上的任意一个节点都小于其子节点,因此这样保证了每次出队的时候都是出树顶的数据。PriorityQueue是通过数组实现的,我们可以对二叉树节点进行编号,从上到下,从左到右,那么每一个节点的编号其实就是其所在数组的索引,这样我们就能通过数组索引来访问对应的节点。数组第0个元素就是树顶,其子节点是第1个和第2个元素,第1个元素的子节点是第3和第4个元素,以此类推,第n个元素的子节点是 2n+1和2(n+1)。同样,第n个节点其父节点是(n-1)/2。

有了这些概念,我们来看下PriorityQueue是如何入队的:
当一个元素入队时,我们会先假装他现在在队列的末尾,然后比较当前节点和父节点的大小,如果小于父节点就将自己和父节点交换,重复此过程一直到当前节点不小于父节点或当前节点是头结点为止,我们将这一流程称为“上浮”。即新节点会不断和当前父节点进行比较,如果小于父节点就会上浮。
再来看PriorityQueue是如何出队的:
我们知道出队的必然是树顶也即数组0位置的元素,但树顶出队后就需要选拔出新的树顶来占据数组0这个位置,这样又会空出来一个位置,依次类推,会不断的变换树的形状。但无论怎么变,出队都是做了-1操作,即假设当前树节点共n+1个,出队后树节点还剩n个,数组内的很多元素都会移动,最终数组0位置的元素会被新的填充,数组n位置的元素会被清除。这样一看,其实出队就是我们从当前数组中选拔出新的位置0的元素,并且将数组n位置元素安排到恰当的位置。因此出队的逻辑如下:
我们先取出数组n位置的元素,命为n,将当前出队的树顶元素得到,命为x。得到x的两个子节点,如果两个子节点都大于n,那么就将n与当前x交换,出队完成。否则如果这两个子节点有比n小的,就将x与较小的那个子节点交换,重复获得当前x的子节点,再次比较,如果一直交换到x不再具有子节点(最后一层),就将x于n交换。这样在树顶元素x与其子节点不断交换的过程中,我们可以成为“下沉”。
其入队和出队的代码如下:
/**
* 优先队列,本质是完全二叉树,通过数组实现
* @author coderZoe
* @date 2021/12/30 16:56
*/
public class PriorityQueue<E> {
private final Object[] elementData;
private int size;
private final Comparator<? super E> comparator;
public PriorityQueue(int capacity, Comparator<? super E> comparator) {
this.size = -1;
this.elementData = new Object[capacity];
this.comparator = comparator;
}
/**
* 入队
* @param e 入队的元素
*/
public void enq(E e){
size++;
//判断数组为空的情况
if(size==0){
this.elementData[size] = e;
}else {
int index = size;
//上浮操作
while (index > 0){
int parentIndex = getParentIndex(index);
@SuppressWarnings("unchecked")
E parent = (E) elementData[parentIndex];
//如果当前节点比父节点小,就将父节点与当前节点交换,交换直到当前节点不大于父节点
if(comparator.compare(e,parent)>=0){
break;
}
this.elementData[index] = parent;
index = parentIndex;
}
this.elementData[index] = e;
}
}
/**
* 出队
* @return 返回头部元素
*/
@SuppressWarnings("unchecked")
public E deq(){
if(size==0){
return null;
}
//出队的数据
E head = (E) this.elementData[0];
//尾节点数据
E last = (E) this.elementData[size];
//清空数组尾节点数据
this.elementData[size] = null;
size--;
//树节点个数大于1个才会需要改变数的结构
if(size!=0){
int headIndex = 0;
//下沉直到当前节点不再有子节点位置
while (headIndex < size/2 ){
int minChildIndex = getLeftChildIndex(headIndex);
E minChild = (E) this.elementData[minChildIndex];
//得到更小的子节点
int rightChildIndex = getRightChildIndex(headIndex);
if(rightChildIndex < size && comparator.compare((E)elementData[rightChildIndex],minChild) < 0){
minChildIndex = rightChildIndex;
minChild = (E)elementData[rightChildIndex];
}
//如果更小子节点都大于last节点,将last节点与当前节点交换 出队完成 退出循环。
if(comparator.compare(minChild,last)>0 ){
break;
}
//否则 将当前节点与更小的那个子节点交换
this.elementData[headIndex] = this.elementData[minChildIndex];
headIndex = minChildIndex;
}
//会走到这代表当前节点没有子节点了,将当前节点与last节点交换
this.elementData[headIndex] = last;
}
return head;
}
private int getParentIndex(int index){
return (index-1)/2;
}
private int getRightChildIndex(int index){
return 2*index+2;
}
private int getLeftChildIndex(int index){
return 2*index+1;
}
}有了这个基础后我们再来看JDK中PriorityBlockingQueue的实现:
PriorityBlockingQueue类在PriorityQueue中多加了一个独占锁和一个信号量,独占锁是为了保证线程安全的,而信号量是保证在队列为空时出队进行阻塞。另外因为PriorityBlockingQueue是无界集合,即会自动进行扩容,所以不存在入队时的挂起,只会有出队时的挂起。
入队:
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
//加锁
lock.lock();
int n, cap;
Object[] array;
//扩容
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
//上浮
if (cmp == null)
siftUpComparable(n, e, array);
else
siftUpUsingComparator(n, e, array, cmp);
size = n + 1;
//通知因队列为空而出队时挂起的线程
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
//上浮函数 这里与我们之前写的逻辑基本一样
private static <T> void siftUpUsingComparator(int k, T x, Object[] array, Comparator<? super T> cmp) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (cmp.compare(x, (T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = x;
}出队:
public E poll() {
final ReentrantLock lock = this.lock;
//加锁
lock.lock();
try {
//出队
return dequeue();
} finally {
lock.unlock();
}
}
//出队操作
private E dequeue() {
int n = size - 1;
if (n < 0)
return null;
else {
Object[] array = queue;
E result = (E) array[0];
E x = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
//下沉
if (cmp == null)
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
//下沉操作 与我们之前写的逻辑基本一样
private static <T> void siftDownUsingComparator(int k, T x, Object[] array,int n,Comparator<? super T> cmp) {
if (n > 0) {
int half = n >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = array[child];
int right = child + 1;
if (right < n && cmp.compare((T) c, (T) array[right]) > 0)
c = array[child = right];
if (cmp.compare(x, (T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = x;
}
}阻塞出队:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
//做了一个阻塞挂起 如果当前队列为空 就用条件变量挂起
while ( (result = dequeue()) == null)
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}4.4 CopyOnWriteArrayList
CopyOnWriteArrayList的源码是很简单的,但是要看懂源码需要先了解CopyOnWrite思想,这一思想及其的重要,其使用场景也非常广泛,如OS下fork一个子进程,Redis的RDB,Kafka的客户端内存缓冲区。
在说COW前我们先说下如何实现一个线程安全的List集合,比较简单的方法就是加锁,如果想效率比较高可以加读写锁。但如果是读多写少的场景,我们加读写锁会有什么影响呢?首先我们知道读写锁的写写操作和读写操作是互斥的,当某个线程在写入的时候,不允许其他线程读取。这样假设我们在高并发读取的情况下偶尔插入一条写请求,那么其他读线程可能都会阻塞,这肯定不满足我们的需求的。我们更想要的是一种在读取的时候能够不阻塞,并且在写入的情况下也不会影响读取的List。
这就引入了COW,COW就是写时复制,它被广泛的应用于读多写少的场景。在写入的时候会拷贝一份原始数据的副本,然后在副本数据上执行修改(写入)操作,此时读取操作还是读的原始数据,并不会因为写入受影响,因此也不会阻塞读取。修改完成后再将原始数据替换为副本数据。然后Java下会通过volatile关键字通知数据被修改,保证读线程对修改的可见性。
但是需要注意的是,CopyOnWriteArrayList只适合读多写少的场景,因为在写入的时候,写写线程也是互斥的,同时每个写线程还会执行一次数据复制操作,因此更耗时。
下面我们看下CopyOnWriteArrayList的源码实现
首先CopyOnWriteArrayList的属性很少,关键的只有如下两个:
public class CopyOnWriteArrayList<E>{
//独占锁,用于写写互斥
final transient ReentrantLock lock = new ReentrantLock();
//List的底层实现,就是数组 加了volatile关键字,保证修改的可见性
private transient volatile Object[] array;
}add 操作
public boolean add(E e) { //加独占锁,写写互斥 final ReentrantLock lock = this.lock; lock.lock(); try { //获取数组 Object[] elements = getArray(); int len = elements.length; //cow思想,copy一份原始数据 Object[] newElements = Arrays.copyOf(elements, len + 1); //将新的数据插入到复制的副本数据中 newElements[len] = e; //将原始数据替换为副本数据 setArray(newElements); return true; } finally { lock.unlock(); } } final Object[] getArray() { return array; } final void setArray(Object[] a) { array = a; }remove操作
public E remove(int index) { //加独占锁 final ReentrantLock lock = this.lock; lock.lock(); try { //获取数组 Object[] elements = getArray(); int len = elements.length; E oldValue = get(elements, index); //numMoved是删除数组的下角标位置(这个下角标是倒着数的位置,比如要删除最后一个元素,此时numMoved就是0) int numMoved = len - index - 1; //删除的是最后一个元素 if (numMoved == 0) //直接截取1~length-1的数组即可,将最后一个位置裁掉 setArray(Arrays.copyOf(elements, len - 1)); else { //否则,代表删除的元素不是最后一个 Object[] newElements = new Object[len - 1]; //执行两段拷贝,将要删除的元素从数组中剃掉 //0~index和 index+1~length System.arraycopy(elements, 0, newElements, 0, index); System.arraycopy(elements, index + 1, newElements, index, numMoved); //替换新的Array setArray(newElements); } return oldValue; } finally { lock.unlock(); } }get操作
public E get(int index) { //直接读取 不加锁 return get(getArray(), index); }
